Overview
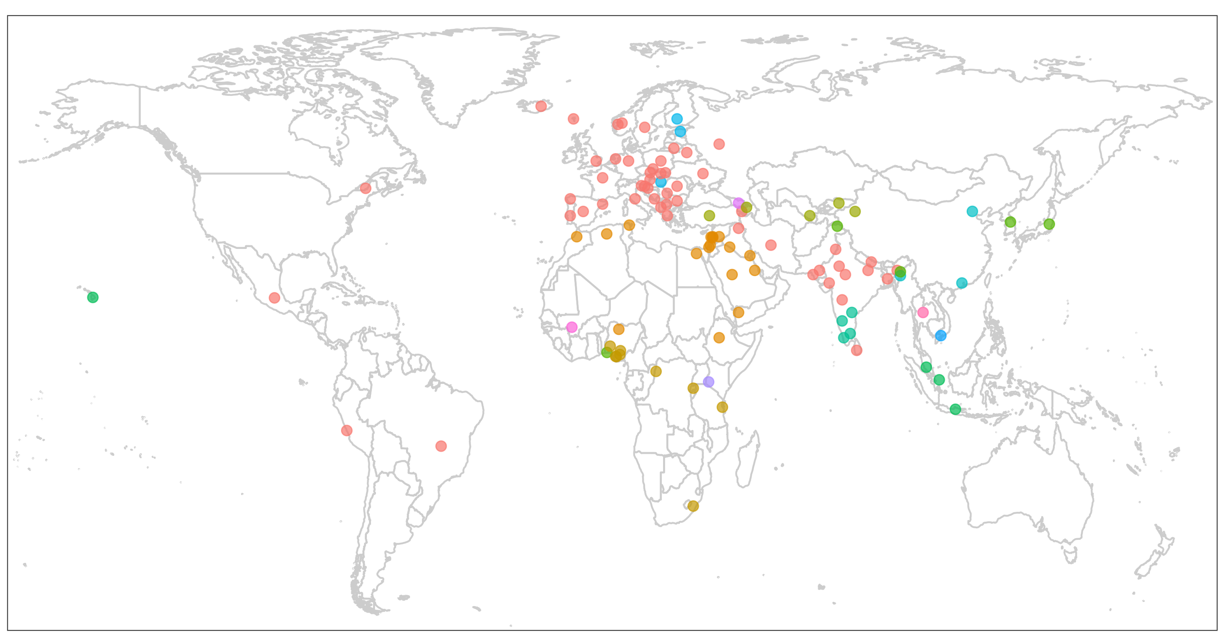
Many languages lack culturally-specific evaluation datasets created by language community members themselves. The MRL 2025 Shared Task invited contributors to create manually-annotated physical commonsense reasoning datasets for their language(s).
The format follows PIQA, a physical commonsense reasoning benchmark where each example consists of a prompt ("goal") with two candidate completions ("solutions"). The result is Global PIQA, a collaboratively constructed multilingual physical reasoning benchmark with broad language coverage and culturally-specific examples.
All authors of accepted submissions were included on the resulting benchmark paper. The shared task has concluded, however there is still an opportunity to contribute — we are accepting submissions for any language or variety not currently in Global PIQA. We especially invite submissions for low-resource languages and non-prestige varieties.
Task & Submission Format
The MRL 2025 Shared Task accepted submissions of non-English PIQA-style datasets with accompanying dataset description papers.
Example items
{
"prompt": "When a light metal cup falls off a counter,",
"solution0": "it will shatter after hitting the ground.",
"solution1": "it will bounce after hitting the ground.",
"label": 1
}
// Example 2 — materials knowledge
{
"prompt": "What's the best material for a DIY walking stick?",
"solution0": "A discarded tree branch.",
"solution1": "A discarded lead pipe.",
"label": 0
}
Still want to contribute?
Global PIQA is no longer accepting submissions, but fill out the interest form and we'll be in touch about future projects!
Contact
Questions about the shared task? Reach out to the organizers.
Email: mrlbenchmarks@gmail.com
Twitter/X: @mrl_workshop
Bluesky: @mrl-workshop.bsky.social
Discord: Join here!