Overview
Last year, over 350 contributors from around the world came together to create Global PIQA. This dataset evaluates culturally specific commonsense reasoning performance for over 100 language varieties. All contributors were invited to be authors on the dataset.
The 2026 Shared Task will again involve making a community-led dataset of language- and culture-specific QA items. All accepted submission authors will be included on the resulting benchmark paper. We especially encourage participation from speakers of low-resource languages and non-standard or non-prestige varieties.
2025 Results Now Available
Global PIQA v0.1 was released in October 2025. Explore the dataset on Hugging Face or read the preprint. See the 2025 Shared Task page for full details.
Task Format
The full description of the task format can be found here. Contributors should submit question-answer pairs for language- and culture-specific knowledge.
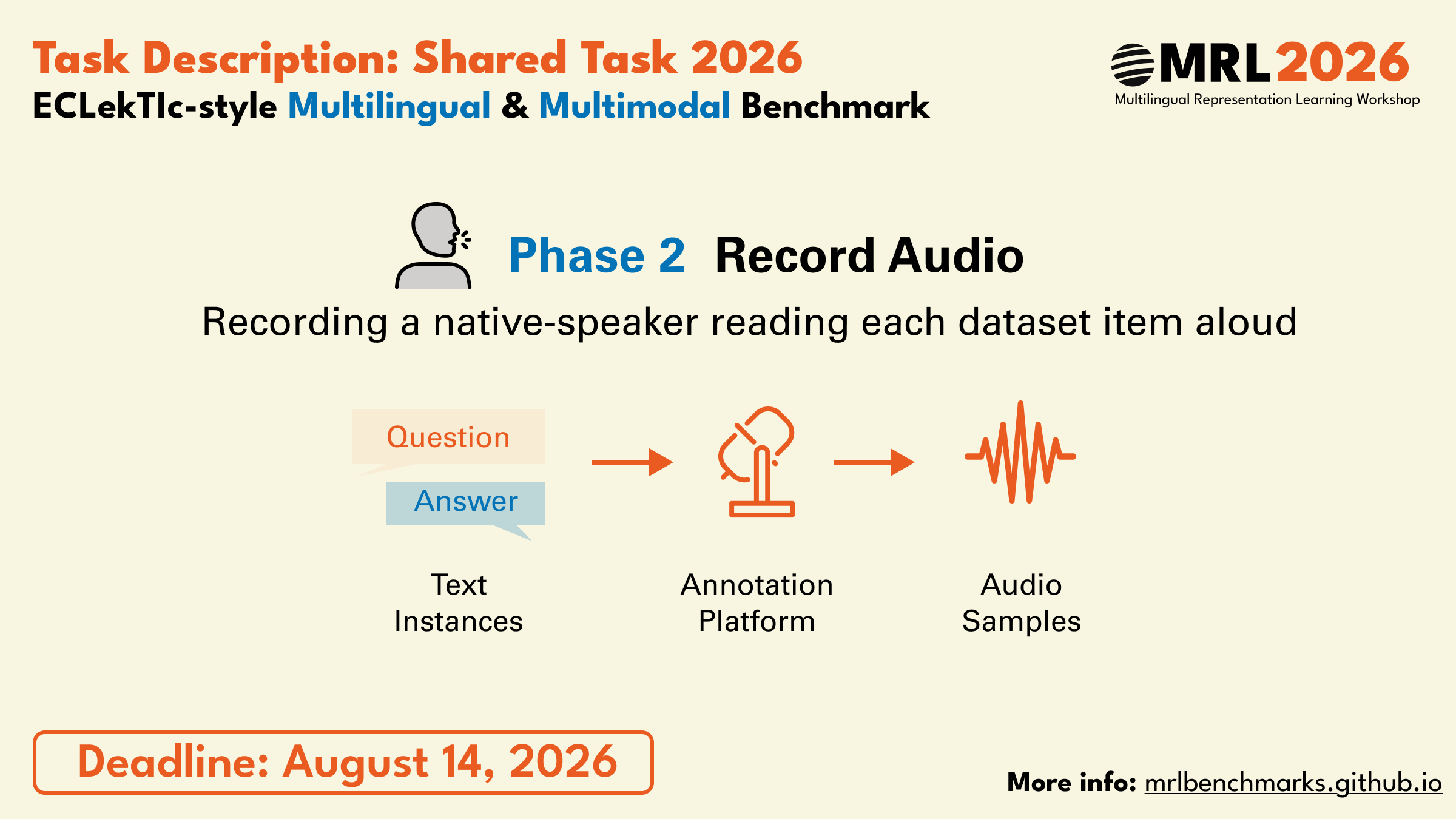
First, contributors will create text question-answer pairs.

After being approved by the organizers, contributors will receive instructions about recording and submitting audio recordings of the items they wrote.
Here is an example of a potential question:
"question": "In deutschsprachigen Filmen, wer synchronisiert Brad Pitt?",
"answer": "Tobias Meister",
"translated_question": "In German-speaking films, who dubs Brad Pitt?",
"translated_answer": "Tobias Meister",
"country": "Germany",
"language": "deu_latn",
"url": "https://de.wikipedia.org/wiki/Tobias_Meister"
}
This format is based on the ECLeKTic dataset, which you can consult for further examples.
Important Dates
All deadlines are Anywhere on Earth (AoE). Dates subject to change — register your interest to receive updates.
Contact
Questions about the shared task? Reach out to the organizers.
Email: mrlbenchmarks@gmail.com
Twitter/X: @mrl_workshop
Bluesky: @mrl-workshop.bsky.social
Discord: Join here!